Machine Learning Techniques for Overcoming Distribution Layer Challenges
Machine learning offers a range of techniques that help manufacturers and distributors overcome the limitations of the distribution layer. These methods make it possible to uncover customer insights and identify high-value opportunities that might otherwise remain hidden. Here’s a six-step process for building and implementing a machine learning–powered SAM model:
1. Align on Goal and KPIs
Begin with a clear understanding of the business goal, in this case, uncovering end-user demand to drive SoW growth. This objective informs what data is needed, which stakeholders must be involved (typically sales and marketing leaders) and what success metrics to track. Relevant KPIs might include SoW growth percentage, seller productivity and percentage growth in net-new end users.
2. Establish a Data Foundation
A robust data foundation is essential. Manufacturers should aggregate data from all available sources, including indirect and direct sales records, distributor performance data and any available point-of-sale (PoS) or distribution data shared by partners. This internal data should be enriched with external firmographic information (e.g., annual revenue, subindustry, employee counts) and relevant market reports.
Data quality and consistency are critical. All records should be unified via shared account IDs and thoughtful fuzzy matching to create a single source of truth. This foundational step ensures that the SAM model is built on accurate, comprehensive data.
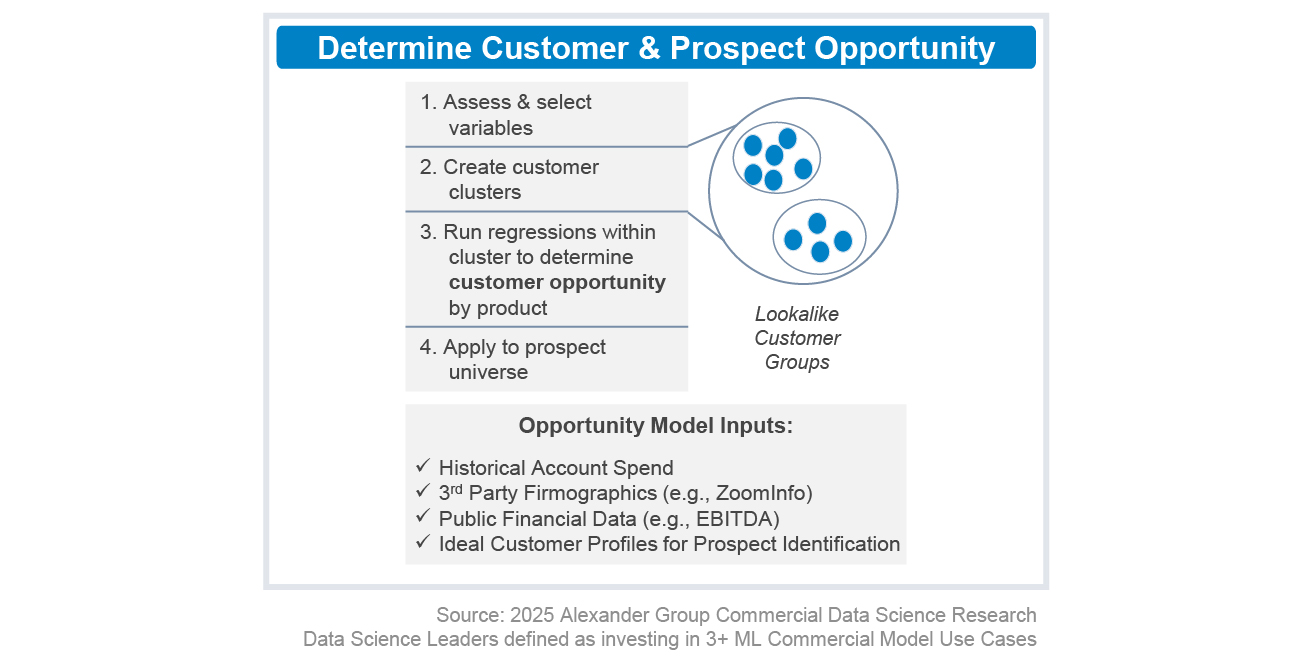
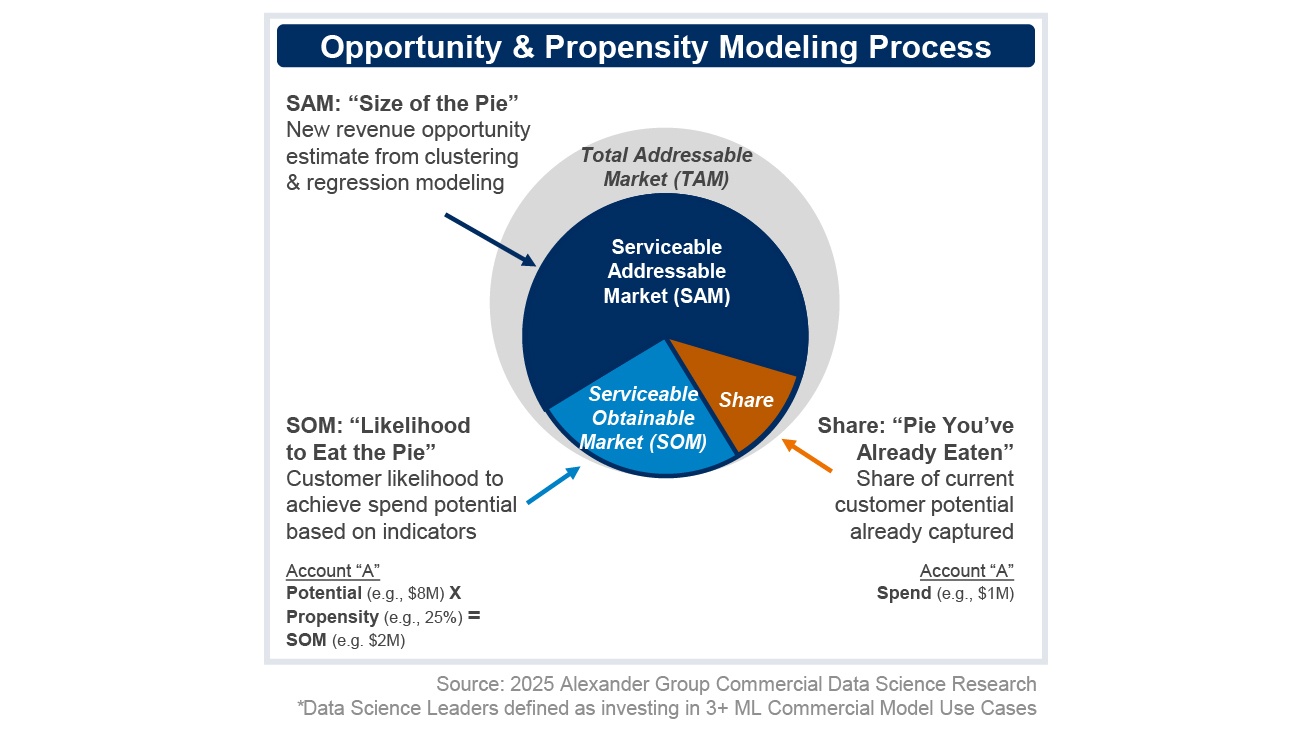
3. Potential Modeling
Spend Potential models estimate a realistic dollar-value wallet size for both current customers and prospects. This should include models for both known current customers and prospects.